別再讓素材在庫裡失蹤。現在就能一秒找到。
AI Autotagger 使用視覺語言模型分析你的圖片與影片(OpenAI、Anthropic、Google、OpenRouter,或本地方案如 Ollama 與 LM Studio),並依你定義的規則把標籤、名稱與描述寫回 Eagle。設計師、攝影師與研究人員每月處理超過1,000萬個項目,他們早就受夠手動打標籤。
為什麼是 AI Autotagger?
多數自動標籤工具都是黑盒。它們猜你想要什麼標籤,卻完全不讓你自訂輸出。最後你只會得到一堆像 “photo” 或 “design” 這種泛用標籤,跟你真正整理素材的思路對不上。
AI Autotagger 不一樣。你可以建立帶有明確規則的 預設:要產生哪些標籤、要不要重新命名、要寫什麼描述,以及 AI 應該如何解讀你的內容。攝影、UI 設計、時尚、OCR、產品照都能用同一套引擎處理,因為指令由你決定。
想讓 AI 辨識光線條件與拍攝角度?加一條規則就好。需要它擷取品牌 Logo 並按公司分類?把指令寫進去。這種彈性讓一個外掛能配合你正在收集的任何內容,而不是把你硬塞進別人的分類法。
主要功能
8 家 AI 供應商可選,也能本地免費跑模型
支援 OpenAI、Anthropic、Google Gemini 與 OpenRouter;也可以用 Ollama 與 LM Studio 在本地免費執行,離線、私密。你也能使用 Claude Code CLI 或 Codex CLI,直接沿用既有訂閱,而不是按每次 API 呼叫付費。
支援自訂模型名稱,所以新模型一發布你當天就能用,不必等外掛更新。
你定義想要的標籤,不讓 AI 亂猜
精準控制要產生哪些中繼資料:
- 標籤:與既有標籤合併,或完全取代。可提供示例標籤(AI 會跟你的風格走),或給固定清單(AI 只能從你的選項中挑)。也能加前綴/後綴,把相關標籤分組。
- 名稱:依內容重新命名項目。把 `IMG_20240115_143052.jpg` 整理成更可搜尋的 `sunset-beach-golden-hour`。
- 描述:詳細說明、OCR 文字擷取或自訂分析。你可以讓 AI 寫一句摘要、完整拆解,或擷取所有可見文字。
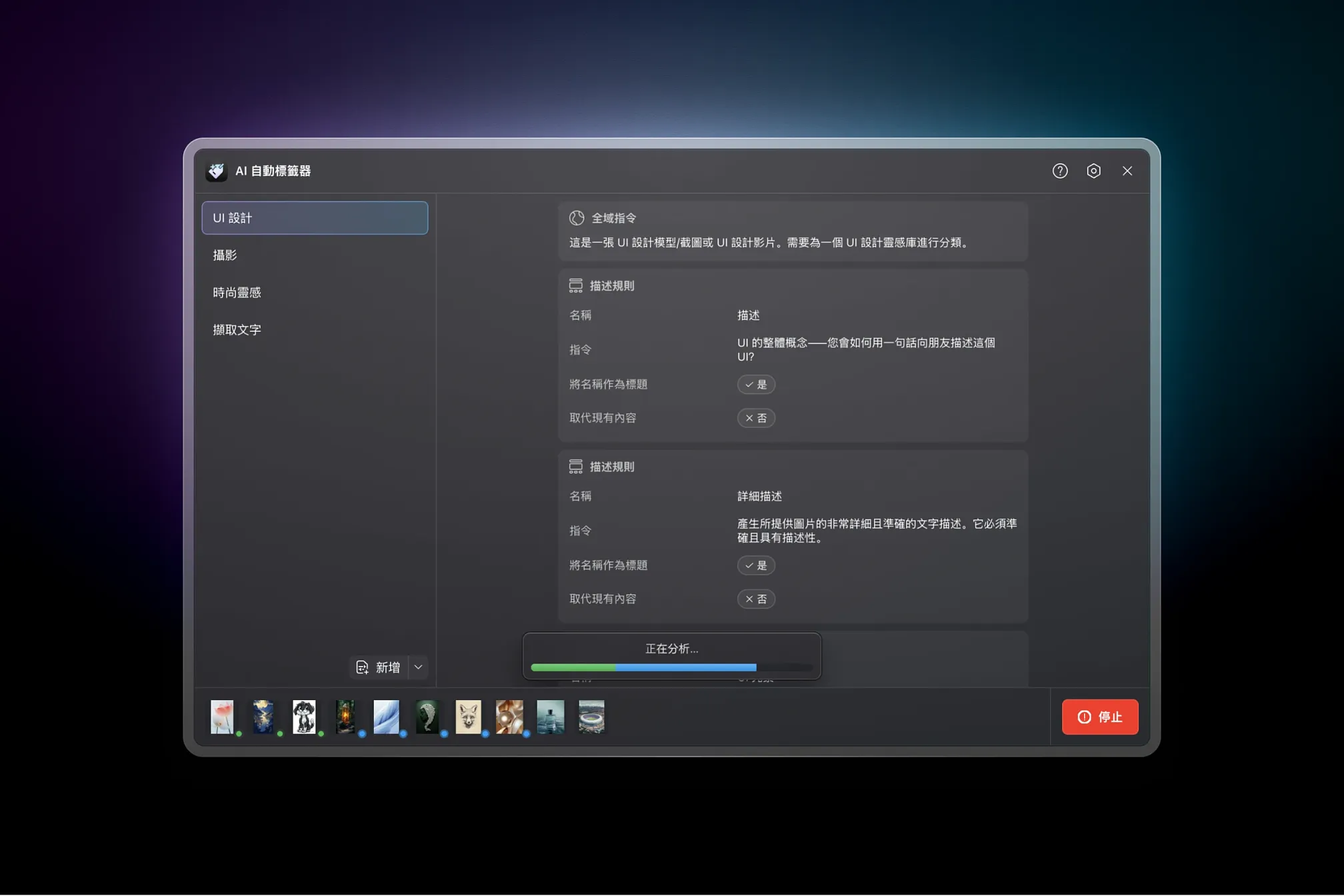
規則以 預設 分組。預設可即時切換以處理不同內容類型:相機匯入先用「攝影」預設,截圖收藏再切到「UI 設計」預設。
6 個內建預設,幾秒上手
開箱即用,立刻開始分析:
- 攝影:辨識主題、光線條件、配色、氛圍與攝影類型。推薦相近創作者,並標註時間帶或季節。
- UI 設計:辨識介面元件(按鈕、卡片、模態視窗)與更高階模式(儀表板、登入表單、定價表)、裝置類型、配色方案與字體風格。擷取可見文字提升可搜尋性。
- 時尚靈感:服裝分類,辨識風格(街頭、高訂、運動休閒),記錄配色、圖樣與材質紋理。偵測年代影響與場景語境。
- 擷取文字:從螢幕截圖、掃描文件與圖片擷取所有可見文字,盡量保留階層與格式。
- 重新命名項目:依內容產生描述性檔名,同時保留原始名稱中的重要資訊。
- 自訂:從零開始,打造你需要的規則。
每個預設都能完全編輯。先用預設值當起點,再把規則調成符合你工作流的樣子。
用自然語言描述預設,AI 直接幫你生出來
不確定預設該怎麼設計?用自然語言描述你想要的結果,AI 會替你寫出預設。
例如:「建立一個用來分類產品照片的預設。我想要產品類型、主色與材質的標籤,並產生短的描述性檔名。」
生成器會輸出完整預設,包含合適的規則、示例標籤與指令。你可以微調,也可以直接使用。
預設用資料夾整理,隨時備份與還原
讓預設管理保持乾淨:
- 資料夾:拖放預設到資料夾,按工作流分組
- 複製:複製預設,做變體的起點
- 匯入/匯出:用 JSON 分享預設,或備份你的設定
- 自動備份:外掛保存快照,出狀況可還原到先前版本
影片要認真分析,不只看縮圖
影片分析會使用多個影格,而不是單張縮圖。外掛會依影片長度用可變採樣率擷取影格:短片每秒取更多影格,長片則在全長度內取代表性樣本(最多 60 個影格)。
這代表 AI 看到的是影片真正發生的內容,而不是 Eagle 剛好拿來當縮圖的那一格。
同一個項目不重複處理
跳過規則可避免對已處理項目重複分析。你可以設定一個跳過標籤:外掛看到項目有該標籤就不處理。也能在處理完成後自動加上跳過標籤,讓每個項目只分析一次。
這讓增量工作流變得實用:只分析新匯入的內容,不必一直重跑整個資料庫。
即時知道你花了多少
Token 使用量與成本估算會隨操作即時更新。成本小工具會顯示目前會話的累計消耗,並按輸入/輸出 Token 拆分。
每個模型的單價都可設定,供應商調價時你可以更新數字,讓估算保持準確。本地供應商(Ollama、LM Studio)會顯示零成本,因為它們跑在你的硬體上。
API key 本地加密,你的憑證就是你的
API key 在保存前會用你設定的密碼加密。密碼本身不會被保存,開始分析會話時會提示你解鎖。
若忘記密碼,你可以重設並重新輸入 key。加密意味著就算有人能存取你電腦的儲存內容,也無法在沒有密碼的情況下讀出你的 key。
一邊工作,一邊跑完整素材庫
可配置並行度,一次處理數百個項目打標籤。選好要分析的內容,按下按鈕,即時看進度。
並行度可從保守(一次 1 個請求)到激進(100 個並行請求)。並行越高越快,但可能因供應商不同而遇到速率限制。需要停下時隨時取消。已完成的會保留,你之後可繼續處理剩餘項目。
支援 8 種語言
完整介面在地化:英文、德文、西班牙文、日文、韓文、俄文、簡體中文、繁體中文。外掛會自動偵測 Eagle 的語言設定。
運作方式
- 在 Eagle 裡 選取項目(要多少都行)
- 從外掛工具列 開啟 AI Autotagger
- 選擇一個預設(或建立符合需求的預設)
- 點選 `執行分析` 並確認你使用的模型
- 看標籤、名稱與描述 即時寫入
就這樣。外掛會處理圖片縮放(可設定解析度,以平衡品質與成本)、失敗自動重試的 API 呼叫,以及把中繼資料更新回 Eagle。你也能用狀態篩選清單,查看哪些已完成、哪些處理中、哪些失敗。
自備金鑰(Bring Your Own Key,BYOK)
AI Autotagger 採用 “Bring Your Own Key” 模式。你在 OpenAI、Anthropic、Google 或 OpenRouter 建立帳號,生成 API key 並貼到外掛中。你直接向供應商按用量付費,沒有中間加價,也沒有訂閱費。
想要完全免費、離線、私密使用:安裝 Ollama 或 LM Studio,下載支援視覺的模型(例如 LLaVA),再把外掛指向你的本地伺服器。你的圖片留在本機,長期成本只有電費。
大家怎麼用它
- 設計師:你存了 3,000 張 UI 截圖,要找那張有儀表板指針圖的?祝你好運。AI Autotagger 會按元件、模式與配色打標籤,所以搜尋 `儀表板 儀表圖 深色模式`(`dashboard gauge chart dark mode`)真的找得到。
- 攝影師:每次拍攝都往庫裡加幾百張。手動一張張打標籤?那是好幾個小時。讓 AI 在你修圖時處理主題、光線、氛圍與類型標籤。
- 研究人員:掃描文件、PDF 截圖、文章剪貼,不做 OCR 就不可搜尋。「擷取文字」預設會把每個字都抽出來,讓你的紙本檔案也能查詢。
- 內容創作者:下載資料夾裡全是 `screenshot-2024-01-15.png` 和 `IMG_4829.jpg`。「重新命名項目」預設會把它們變成 `twitter-thread-design-systems-dark-mode.png`,半年後也能找到。
- 時尚檔案整理者:依風格、年代、品牌、配色與質感整理服裝。建立參考資料庫,讓 “1970s bohemian floral maxi dress” 回傳的就是你期待的結果。
開始使用
- 在 Eagle 中 安裝外掛(偏好設定 → 外掛程式 → 新增外掛)
- 開啟 `設定` 並選擇供應商
- 加入你的 API key(或為 Ollama/LM Studio 設定本地伺服器 URL)
- 選取一些項目 並點選 `執行分析`
自訂 OpenAI 相容提供者,可連接任何支援 OpenAI 格式的 API
AI 預設產生器現在支援 CLI 提供者(Claude Code、Codex)
應用程式內更新通知,重要公告會顯示在更新對話框中
重新整理大量項目選取時顯示警告以防止速度變慢
改進影片處理,ffmpeg 不可用時錯誤訊息更清楚,逾時時間根據影片長度自動調整
修正:特定位置拖放預設不再當機
修正:標籤修飾詞文字現在可以留空
修正:Ollama 自訂模型名稱不再意外重設
- 新增 AI 驅動的預設生成器——以自然語言描述標籤需求
- 新增預設備份與還原工具——自動備份,並支援手動備份/還原
- API 金鑰以密碼保護儲存,支援解鎖並遷移既有金鑰
- 實驗性支援 Claude Code CLI 與 Codex CLI 供應商——使用本機 CLI 工具取代 API 呼叫
- 新增 OpenRouter 供應商——透過統一 API 存取多個 AI 模型
- 各供應商提供進階設定:溫度、最大權杖與思考預算
- 新增應用程式內的說明對話框,包含文件與常見問題
- 新增預設資料夾並支援拖放排序——在側邊欄整理預設
- 可從「預設範本」子選單在「新增」按鈕下拉中加入單一預設範本
- 支援 Claude 4.5、GPT-5.x 與 Gemini 3.0 模型
- 支援簡體中文、繁體中文、德文、日文、韓文、俄文與西班牙文
- 在重新整理或切換預設時即時更新項目狀態
- 改進批次處理時的記憶體管理
- 各種 UI 修正
Fixed: LM Studio and Ollama base URLs couldn't be changed
Fixed: maxTokens error
Added option to process items using their thumbnail images (e.g., SVGs)
Added support for tag modifiers with configurable position and spacing
Improved processing for very large inputs/outputs (e.g., long documents)
Version 7 (Included in this release)
Added Ollama and LM Studio support for local model inference
Improved model selection UI, including allowing custom model names so you can now use the latest models as soon as they're released
Added option to resize items before AI processing (improves speed/cost)
Added Gemini Flash 8B model
Improved UI freezing issues when processing many items
Added detailed logs for each item
Fixed: Item names longer than 245 characters are now truncated to avoid data corruption
Added Ko-Fi button for those who want to support the project
Auto-refresh items when you change the selection in the main Eagle window
Copy and paste presets — share presets with people!
Option to send low-res versions of images/videos to reduce API cost
Improve reliability of Google's Gemini 1.5 models
Various bug fixes and UI improvements
Fix double-paste API key bug on Windows